
Entry 30: Improve Performance - Learning Curves
Learning curves can help determine what avenues to pursue if a model isn’t up to expectations, or worse, is completely unusable. They can also be used to determine whether the training and test datasets are suitably represented.
The notebook where I did my code for this entry can be found on my github page in the Entry 30 notebook.
The Problem
There are several areas to explore when working to improve model performance. Some of these are:
- Get more training data
- Use fewer features
- Engineer new features
- Add polynomials of already existing features
- Decrease $\lambda$
- Increase $\lambda$
Each of these options can be time consuming to explore and implement, so having a way to narrow down what to work on can be extremely helpful. Many times, the direction to pursue can be identified by understanding if the model has underfit or overfit the data. As a reminder:
- Underfiting
- Model generalizes too much and cannot capture trends/patterns
- Model is too simple and has low predictive power on both training and test data
- Example: model with a single feature where the feature cannot predict the target (see the “high bias” example)
- Overfitting
- Model fits too closely or exactly to the training data and cannot generalize to unseen data
- Model is too complex and has low predictive power on test data
- Example: model just memorizes the answers from the training data (see the “high variance” example)
For more on underfitting and overfitting, see Entry 17.
The Options
Learning curves are a very useful tool. They can be used to quickly understand if the model is struggling with high bias (underfitting) or high variance (overfitting). In general, learning curves appear like this:

Note, the code for the three learning curve charts was adapted from the online appendix of the Python Data Science Handbook. To see my code for any of the charts, visit the Entry 30 draft.
Bias and Variance
Andrew Ng provides good basic information on what to expect from models with high bias vs those with high variance in his Machine Learning course “Video: Learning Curves” lecture of week 6.
For a refresher on bias, variance, and regression scoring methods see Entry 21.
High bias
In cases with high bias, the model simply doesn’t fit the data well. Such as a simple linear model being fit to a logarithmic curve.
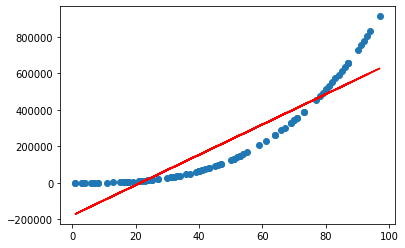
The model has fit the data as well as can be reasonably expected, so the train error and test error come close to convergence. However, the overall error will be high.

In these cases, additional training data won’t improve model performance because the model has learned all it can from the non-linear data.
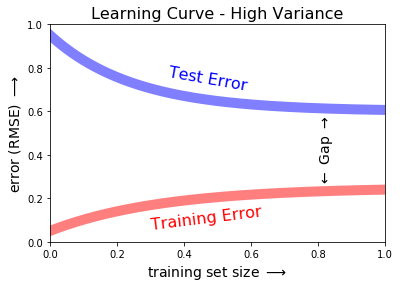
High variance
In cases with high variance, the model overfits the data, which can become exacerbated with additional training data.
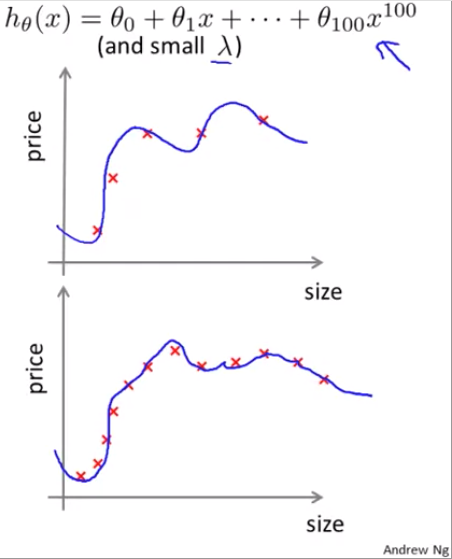
Since the model is overfit, the training error will be low and relatively flat. However, the test error will remain high and there will be a large gap between the training error and test error.
The Proposed Solution
While these rules of thumb don’t hold true for every case, following these guidelines will help decide what areas to focus on to improve model performance.
High Bias
For models suffering from high bias, productive avenues to pursue include:
- Add new features
- Add polynomials of already existing features
- Decrease $\lambda$
High Variance
For models suffering from high variance, productive avenues to pursue include:
- Get more training data
- Smaller set of features
- Increase $\lambda$
The Fail
The above charts are beautiful, and the theory from the Machine Learning course on how to identify high bias vs high variance is laid out very intuitively. However, per usual, the real data didn’t conform to the pretty theory.
Where did I turn when I got these incomprehensible results? Jason BrownLee of Machine Learning Mastery of course!
I started at the beginning of his Learning Curves post and almost immediately found some interesting information about applied learning curves: the metric used can be minimizing or maximizing.
The minimizing vs maximizing option explained why the learning curves in Hands-On Machine Learning and the Machine Learning course looked one way and the charts in Python Data Science Handbook looked another way. In the first case, they were using a minimizing function (RMSE; where the aim is to get as low a value as possible). In the second case, he was using a maximizing function (the score; where the aim is the get the value as high as possible).
Side note, there is a function in Scikit-Learn sklearn.model_selection.learning_curve that will generate the learning curve and it also uses a maximizing function - generally the default scoring method of the underlying algorithm.
Bias and Variance
Okay, let’s try this again.
High Bias
High bias (underfitting) can be identified just from the training learning curve.
My attempts at using Linear Regression on the house_16H dataset from openml look like a good example of this. The unscaled version is all over the place at the beginning, but even after scaling the features, the RMSE settled in around 40,000. These results indicate that a linear model probably isn’t the best choice.
Jason pointed out another case where the model is underfit, but that more data is needed (remember, when data is underfit, Andrew Ng stated that most of the time, more data won’t help). In this case, the learning curve for the training data continues to slope downward.
Notice in Jason’s example, that there are only 50 samples. This gives a strong indicator as to why the loss function hasn’t evened out: the model hasn’t trained on enough data to converge on an answer. Jason puts it succinctly in his post:
This indicates that the model is capable of further learning and possible further improvements and that the training process was halted prematurely.
I.e. when you encounter this, get more data.

High Variance
Jason lists the two criteria of overfitting on a learning curve as:
- The plot of training loss continues to decrease with experience
- The plot of validation loss decreases to a point and begins increasing again

Other
In Jason’s High Variance example, I find it interesting how much more variation there is in the curves (the lines are squiggly instead of smooth). I noticed this because of the high variability in the learning “curve” for the Boston dataset in my accompanying notebook. There is a spike in RMSE in the examples from around 70 to around 110. This “curve” is very atypical compared to the theory and examples in all of my resources.
In attempting to reconcile this phenomenon with high bias vs high variance, it occurred to me that there is a different explanation that is more likely. Drastic changes in the score of a model can be due to the subsample of examples it’s trained on. I talk about this in the Stratification section of Entry 17.
A possible culprit on the Boston dataset would be if there was a section of outlier prices. The model would train well at the start when there was a mixture of prices. Then when it hit the subset of outliers, let’s say all super expensive houses, that would significantly change the model’s predictions - in an undesirable way. Once the training examples return to the normal mixture, the predictions return to their former performance.
Including a cross validation component to my implementation of the learning curves may reduce or remove this condition. However, this feels like something that’s good to know. When I start working on improving models, I’ll want to know how sensitive a model is to the training examples. Having results like this in the learning curve will tell me this information and I can try different data splitting methods to control it.
Up Next
Resources
- Learning Curves - online appendix of the Python Data Science Handbook
- Python Data Science Handbook
- Machine Learning course
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
- How to use Learning Curves to Diagnose Machine Learning Model Performance
- sklearn.model_selection.learning_curve