
Entry 20: Scikit-Learn Pipeline
There are quite a few steps between pulling data and having a trained model. I need a good way to string it all together.
The notebook where I did my code for this entry can be found on my github page in the Entry 20 notebook.
The Problem
As discussed in Entry 17, pre-processing and training steps need to be performed on each split when running cross-validation.
Pre-processing steps include:
- Determining best features from collinearity with the target
- Removing multicolinear features
- Centering and scaling features
Training steps include:
- Stratifying categorical data
- Splitting into k-folds
- Training a specific type of model
- Scoring the model
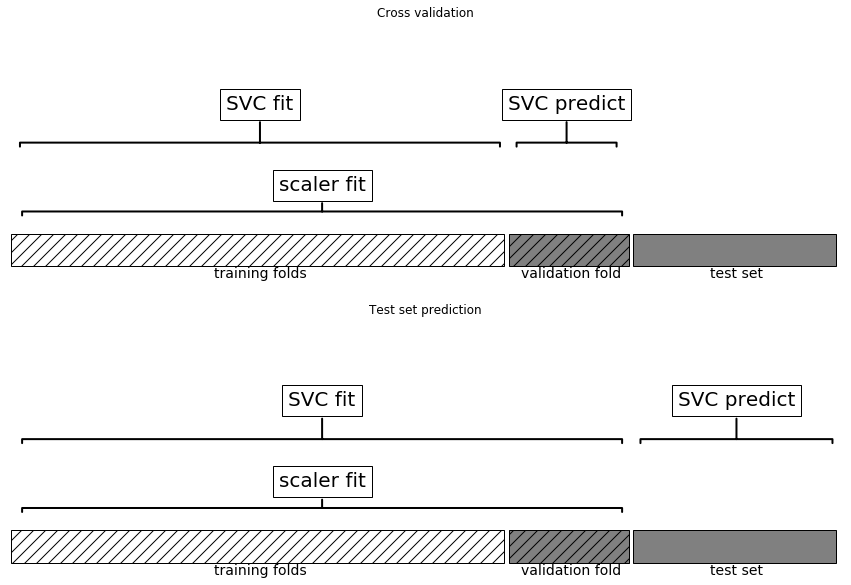
To prevent data leakage, the order of these steps matters. Without the proper process in place, it is easy to get data leakage. The cause of the data leakage can be easily seen in the chart below, courtesy of the mglearn package. This package was created to supplement Introduction to Machine Learning with Python by Andreas Muller and Sarah Guido.
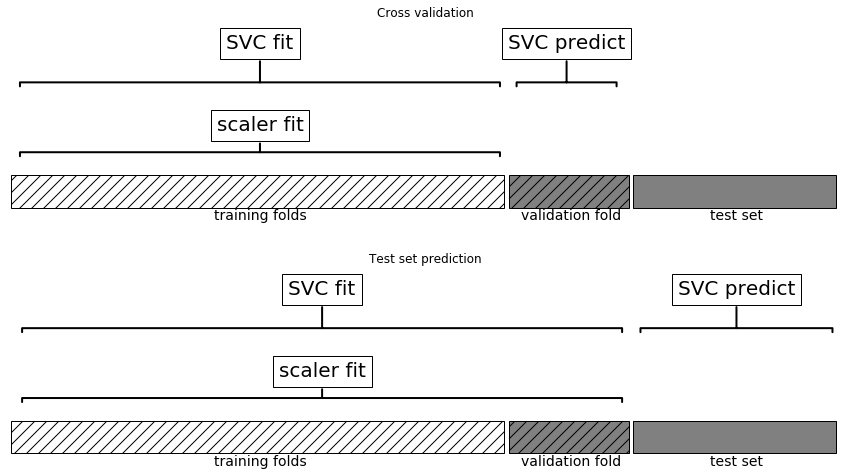
The correct way implement cross-validation with pre-processing is to do the pre-processing on only the training folds of each split. This can be seen in the chart below, also courtesy of the mglearn package.
The difference is subtle: you can see it in the top portion of the charts in how much data scaler fit uses.
The Options
High level
Pipelinemake_pipelineColumnTransformermake_column_transformer
Pipeline and make_pipeline
Scikit-Learn has a Pipeline feature with a convenient make_pipeline function. Using Pipeline requires specifying a name for each step. The make_pipeline function automatically names the steps for you.
The pipeline applies the exact same transformations to all features. There’s no way to change the handling of categorical and numerical columns using just this option.
ColumnTransformer and make_column_transformer
The ColumnTransformer capability was added in 2018. This function takes definitions of column subsets and applies designated transformations to only those columns. By default, untransformed columns are dropped, but there is a parameter remainder that accepts the value passthrough to include untransformed columns as well.
ColumnTransformer only transforms the specified columns, it cannot do any transformations on the full training set or include an estimator.
Specifics
Selecting numeric vs categorical columns
The way I select columns by type (i.e.: categorical, numeric, object, etc) with pandas is to use the .select_dtypes method. This has worked well in the past. It allows for inclusion or exclusion of column types.
Scikit-Learn’s compose module has a function called make_column_selector. This option is even more flexible than .select_dtypes. It does inclusion/exclusion of column types just like .select_dtypes and also allows for the specification of a regex pattern. I can see this being useful in a situation in which a group of features is named something similar (ex: word_count_all, word_count_vowels, word_count_consonants, etc) and I want to apply a transformation to that similarly named group.
As an added bonus, the DataFrame doesn’t have to be specified by name using make_column_selector, making it easier to incorporate into a pipeline that can be applied to different datasets.
The Proposed Solution
Pipeline and ColumnTransformer each address a need the other cannot meet. When creating a pipeline for mixed types, both are needed to create a complete pipeline.
From what I can tell, it doesn’t matter if the base function is used or the make_ function is used. The only difference I saw was that the base function requires an explicit name where as the make_ variation creates a name on its own. See the examples in Column Transformer with Mixed Types and sklearn.compose.make_column_transformer to see this in action.
The Fail
Remember back in Entry 2 when I said that I owned the first edition of Hands On Machine Learning and not the second? That’s not true anymore. Which turned out to be a good thing for this entry. The ColumnTransformer() function wasn’t added to Scikit-Learn until September 2018, so there was no way it could have been included in the first edition of Hands On Machine Learning which was published in 2017. But he made sure to include it in the second. I also like the addition of color to the new edition. It makes the code stand out and the book easier to use as a reference instead of having to read it cover to cover.
Method to use on pipeline
It took a while to figure out whether to use .fit() or .fit_transform() with a pipeline created with the make_pipeline() function. I pieced together the solution from a couple of the answers on this StackOverflow question. The verdict: use .fit().
The pipeline passes the output of one line to the next. Transformers accept the .fit() and .transform() methods whereas estimators accept the .fit() and .predict() methods. The pipeline can accept fit_transform if it ends in a transformer, but not if it ends in an estimator. For maximum flexibility, I’ll use .fit() going forward.
Cross-validation metrics
Finding the names of the metrics that work with the cross-validation functions was harder than it should have been. I finally triggered an error that clued me in to the function that would list all available options: sklearn.metrics.SCORERS.keys(). I still have to separate out which metrics are for continuous variables and which for classification, but I’ll address that in the metrics section of this series.
Also, the classification dataset I used had three classes instead of two. The logistic regression metrics wouldn’t run because it was a multiclass problem. I just ran the continuous metrics instead. I’ll work on which metrics go with what kind of problem in the next set of entries.
Up Next
Resources
- Introduction to Machine Learning with Python
- Column Transformer with Mixed Types
- Scikit-Learn Pipeline Examples
- Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow
- Automate Machine Learning Workflows with Pipelines in Python and scikit-learn
- Python - What is exactly sklearn.pipeline.Pipeline?
- A Simple Guide to Scikit-learn Pipelines
- Introducing the ColumnTransformer
- Managing Machine Learning Workflows with Scikit-learn Pipelines Part 1